
By: Ron Miller | Published: December 1, 2024
Logging best practices: Why we need log IDs
Logs are one of the basic signals an application or service can send—a simple, timestamped piece of information. But throw a ton of those on the backend, and you'll be able to do all kinds of rich analysis later. At least, that's the promise. In theory, you should be able to filter, aggregate, and "slice and dice" that data until you home in on some insight. But in practice, looking through logs mostly feels like looking for a needle in a haystack. Allow me to propose a concept that will make working with logs much easier: the log ID. With this in your toolbox, you'll find that analyzing and aggregating large amounts of logs is much easier.
A log ID is a static identifier for each log statement in the source code. It doesn't change when the log moves to a different line of code, file, or class. If you're logging from multiple services to a centralized logging system (as you should be), this identifier will be unique, even across those services. In your logging backend, the log ID will have a dedicated field or column so that you can filter by that field. Here's how it might look in JavaScript:
log.info(message, "e7yT3");
This log ID should be a parameter in the log function, which makes it both easier to implement and easier to search for—from logs to code and vice versa.
Why We Need Log IDs
Consider a scenario where all your logs have such an ID. Now, instead of relying on the error-prone "log patterns" feature that some log management backends have, you can just filter by the log ID field with 100% reliability.
This kind of filtering is very useful for aggregations. Let's say you have a log that's written every time a user clicks on the "Cart" button on your eCommerce site. Users often go to their cart and then go back for more shopping. Alternatively, a user might go to the cart several times but end up not buying anything. Adding an identifiable log means you can easily create a query or dashboard that shows the average number of times a user clicks on the cart button in a web session. You can correlate that to the checkout process and find out, for example, that most users who buy something click the cart button 3 times.
Here's an example of measuring that in Obics (ANSI SQL):
WITH grouped_counts AS (
SELECT COUNT(*) AS countCart
FROM Logs
WHERE event_id = 'cart1'
GROUP BY sessionId
)
SELECT AVG(countCart) AS average_count
FROM grouped_counts
A results might be:
| average_count |
| 4.2 |
Another way log IDs can be used is to extract information. For example, if you have a log that says what item a user just bought, you can build a query that finds the most commonly bought items. Let's say the relevant log is:
log.info(JSON.stringify({"itemBoughtName": itemName,
"quantityBought": quantity }), "buItem");
Here's how such a query would look in Obics (ANSI SQL):
SELECT JSONExtractString(Message,'itemBoughtName') as item,
JSONExtractInt(Message,'quantityBought') as quantity
FROM Logs
WHERE event_id = 'buItem'
ORDER BY quantity DESC
LIMIT 3
The output might be:
| item | quantity |
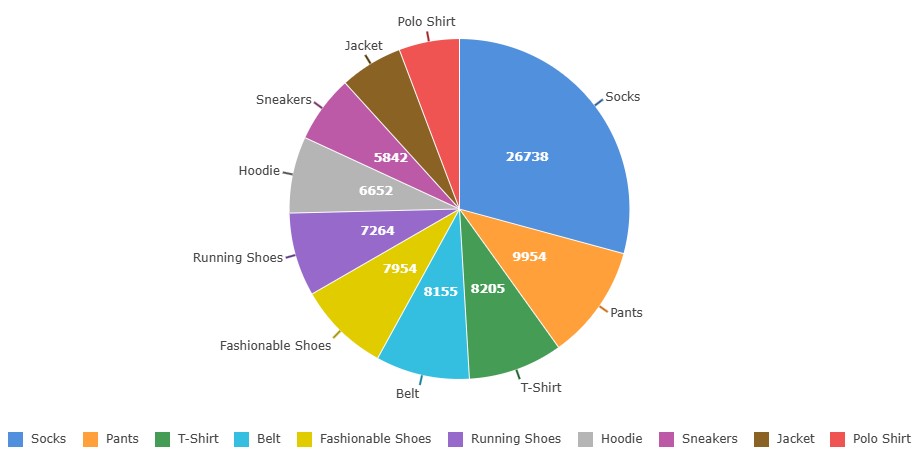
| Socks | 26732 |
| Pants | 9954 |
| Shirt | 8205 |
Another advantage of log IDs is the ease of correlating events. But that requires a logging backend that allows analytics with JOIN. For example, let's say you've launched a new sales campaign that gives a 15% discount when using the coupon code "SUMMER_SALE_15". Some time later, you want to find out which item was the bestseller when using that coupon code. Assuming you have a log that prints the bought item, the classic approach would require adding a field to that log showing all coupons used. But that requires a lot of planning ahead—you shouldn't have to know in advance that you'll want to find out a correlation between a coupon code and bought items. You might have initially thought you'd want different statistics, like the correlation between the coupon code and total sales, or the correlation between the coupon code and a geographical area.
When you have log IDs and JOIN capabilities, you can find such correlations without adding any fields, as long as you have an event for "coupon used" and another event for "item bought." For example, here's a query in Obics that shows the 10 most bought items using the coupon code "SUMMER_SALE_15":
SELECT JSONExtractString(A.Message,'itemBoughtName') as item,
SUM(JSONExtractInt(A.Message,'quantityBought')) as quantity
FROM tmp AS A
INNER JOIN tmp as B
ON A.sessionId = B.sessionId
WHERE A.event_id = 'buItem' AND B.event_id = 'cpnAA' AND B.Message = 'SUMMER_SALE_15'
GROUP BY item
ORDER BY quantity DESC
LIMIT 10
VISUALIZE PIECHART
Implementing log IDs
The challenge in implementing log IDs is to have auto-generated and unique IDs. I wouldn't expect developers spending time trying to fill in catchy names for their logs and verifying those names aren't taken. This process should be automated. Here are some ideas of implementing unique log ID generation:
- A build step that goes [with regex] over all log statements with that have an empty log ID parameter and fills in a random identifier.
- A lint rule that marks log statements with an empty log ID parameter as errors and can fix the error by generating a random identifier.
- A CI/CD step that will create another commit with the random identifiers.
Here's a simple implementation for JavaScript with ESLint. It looks for log statements that end with an empty event_id parameter, like this:
logger.info('query.handler: started', '');
Those are marked as error. The linter's fix will generate a random 5-character string, like this:
logger.info('query.handler: started', '3iUtT');
And here's an implementation of such a rule:
// custom-rules.js
module.exports = {
meta: {
type: 'suggestion', // or 'problem' based on preference
docs: {
description: 'Add unique log Identifier to each log statement',
},
fixable: 'code', // This enables ESLint to auto-fix the rule
},
create(context) {
const regex = /.*logger.*(['"]['"])\)/g;
return {
Program(node) {
const sourceCode = context.getSourceCode().getText(node);
const matches = [...sourceCode.matchAll(regex)];
matches.forEach((match) => {
const [foundText] = match;
const startIndex = match.index;
const endIndex = startIndex + foundText.length;
const random = generateRandomString();
context.report({
node,
message: `Replacing empty event_id ${foundText} with a unique event_id ${random}`,
fix(fixer) {
const textInRange = sourceCode.substring(startIndex, endIndex);
let matchIndex = textInRange.indexOf("'')");
let quoteString = "'";
if (matchIndex === -1) {
matchIndex = textInRange.indexOf('"")');
quoteString = '"';
}
const [specificStart, specificEnd] = [startIndex + matchIndex, startIndex + matchIndex + 2];
return fixer.replaceTextRange([specificStart, specificEnd], quoteString + random + quoteString);
},
});
});
},
};
},
};
function generateRandomString(length = 5) {
const characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
let result = '';
for (let i = 0; i < length; i++) {
result += characters.charAt(Math.floor(Math.random() * characters.length));
}
return result;
}
// eslint.config.mjs
import replaceRegexMatchRule from "./custom-rules.js";
/** @type {import('eslint').Linter.Config[]} */
export default [
...
{
...pluginReact.configs.flat.recommended,
rules: {
...
"custom/replace-regex-match": "warn",
},
plugins: {
custom: {
rules: { "replace-regex-match": replaceRegexMatchRule }
}
},
},
];
This code will do the job, but it has some potential problems. For one, it doesn't guarantee uniqueness. In theory, you could generate the same 5-letter string twice. It's just unlikely. A simple solution would be to keep a hash set of all existing logs and then verify against it with each new log generation.
Another approach would be to generate full-blown GUIDs, in which case uniqueness is guaranteed, but those aren't very convenient to work with.
Yet another problem can occur if you have multiple services for which you want unique log IDs. Each one will have a different linter that won't be able to compare uniqueness against the other services. One easy solution here would be to add a different prefix or postfix to each service's log ID. Or you could do some math magic where each service has a "seed" number, and a generated ID from seed X can never be the same as an ID from seed Y.
In any case, the initial work of getting this right is going to be very worth it once you can utilize this power in the analysis stage.
Finishing Up
When we're talking about structured logs, we're usually talking about JSON structure vs. regular text. That approach is useful—[in a classic log management solution like Elastic]—when each log prints the same fields. While that's fine for metadata fields that you're passing with each log, it doesn't scale well when you have more and more data you want to analyze. In a way, more structured logging means adding log IDs, and the "JSON vs. regular text" issue becomes less important. Log IDs make filtering, aggregation, and querying easier and more reliable. And even more power comes when you combine log IDs with an OLAP-capable analytics backend.